
翻译:GPT-3.5 & DeepL
校对:雨宫优子
原文地址:Simply explained: how does GPT work?
正文:
到现在为止,你可能已经听说过OpenAI的ChatGPT,或者其他替代品如GPT-3、GPT-4、Microsoft的Bing Chat、Facebook的LLaMa或甚至谷歌的Bard。它们都是能够参与对话的人工智能程序。它们非常聪明,很容易被误认为是人类,并且在各种任务上都很熟练,比如写论文和创建网站。
计算机怎么能进行这样的对话呢?让我们看看它的工作原理。
一种概率方法
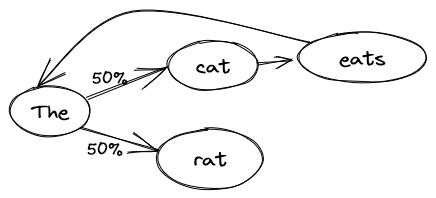
自然语言最简单的模型是一个天真的概率模型,也称为马尔可夫链。其思想很简单:拿一篇参考文本,文本越长越好,然后学习单词序列的概率。例如,
The cat eats the rat.
在给定句子“猫吃老鼠”之后,模型会学习到在“猫”之后总是有“吃”,然后是“the”。但在“the”之后,“猫”的概率是50%,而“老鼠”的概率也是50%。我们可以使用这个模型来问不完整的句子之后的下一个单词是什么。如果我们重复这个过程,我们就可以生成整个句子。
如果我们让模型生成一句话,我们可能会得到与训练文本完全相同的东西:
The cat eats the rat. 猫吃老鼠
我们也可能得到:
The rat. 老鼠
The cat eats the cat eats the cat eats the rat. 猫吃猫吃猫吃老鼠
每次我们达到单词"the",模型都可以选择"rat"或"cat"。
当然,我们用于训练模型的文本将更长,但你已经可以看到其中一些问题。如果我们在整个维基百科网站上进行训练,我们可能会得到类似以下的结果:
Explaining his actions, and was admitted to psychiatric hospitals because of Davis’s strong language and culture. 解释他的行为,并因戴维斯强烈的语言和文化而被送入精神病院。
这个句子更加复杂,词汇更丰富,但它没有任何意义,因为模型缺乏上下文:它只使用最新的单词来生成下一个单词。我们可以扩展模型的上下文单词数为2、3或4个(“eat the “后面是 “rat”),但这样我们可能只是重复输入文本的整个部分:维基百科上有多少次确切相同的4个单词序列?
从词语到意义
到目前为止,我们遇到的问题之一是我们一直将单词作为没有意义的字母组来处理。 模型不理解“the”和“a”之间的关系,以及“king”和“queen”之间的关系等。 我们如何从单词中提取含义?试图向计算机解释含义并定义单词是一条死路,任务太复杂了(人们已经尝试了几十年)。 你怎么能代表一个词的意义呢? 好吧,有一件事是计算机完全理解的:数字。 如果我们将单词的含义表示为沿着几个轴的数字,会怎样呢?
例如:在-1(男性)到1(女性)的尺度上,您如何评估这个词?
- 王:-1
- 王后:1
- 桌子:0
- 胡子:-0.9
或者在-1(坏)到1(好)的尺度上,你如何评估这个词?
- 狼:-0.8
- 公主:0.9
- 桌子:0.1
- 礼物:1
或者:从-1(名词)到1(动词)的比例,您如何评价这个词?
- 国王:-1
- 说话:1
- 漂亮:0
通过足够多的用于评估单词的轴,我们应该能够得到单词的大致含义。问题是: 你如何选择这些轴,如何评估所有的单词?这项任务如此复杂,我们让计算机来完成繁重的工作:我们只需告诉它出现在一起的单词具有相关含义。通过足够多的文本,计算机可以确定这些轴及其评估。在我们的猫的例子中,猫和老鼠都是动物(相近的含义),知道“吃”是动物会做的事情是有用的。但在数学教科书中,没有猫或老鼠,因为它们的含义远离教科书中使用的单词。
我们得到的轴往往难以解释:我们可能会发现一些预期的轴,如男性/女性,但大多数都更加复杂,只有与其他轴相结合时才有意义,或者代表多个概念。
这种方法被称为“词嵌入”,将单词表示为数字向量。
从含义到联系
现在我们有了数字表示的含义,可以使用有趣的特性:例如,我们可以将它们相加。这是什么意思呢?嗯,在这里,例如将“美国”和“货币”相加(或者更确切地说,将它们的数字表示相加)将得到“美元”(或者更确切地说,接近“美元”的数字表示)。“美国”+“首都”=“华盛顿”,“吃”+“名词”=“餐”,等等。
我们还可以进行减法运算:比如“国王” - “男人” + “女人” =“王后”,或者“华盛顿” - “美国” +“英格兰” =“伦敦”。
我们还可以用它找到密切相关的词,同义词。
我们如何认识这种联系?
通过使用这种数值化的单词表示,我们可以回到我们最初的模型,但这次是学习关系,而不是单词。然而,由于关系更加复杂,我们将需要更多的上下文。幸运的是,现在我们有了数字,我们可以使用近似值。我们可以学习到关系,例如:“在某个名词和一个名词后面,通常有一个动词”,“动物通常吃,喝和奔跑”,“老鼠比猫小”,“你只能吃比你小的东西”。当然,所有这些都用数字表示。
这些关系非常复杂,所以我们需要大量的文本来训练模型。它们表示为一个方程式:类似于y = a⋅x1 + b⋅x2 + c,但有更多的输入(不同的x1)和参数(a,b和c)。现在,与其按单词从一个概率跟踪到另一个概率,不如为每个轴(如男性/女性)设置一个方程式。总体而言,该模型具有数百亿,甚至数万亿的参数!这使得它可以考虑更大的上下文:
- 20个单词将允许它构建具有正确结构的简单句子。
- 100个单词将允许它在一个小段落中发展一个简单的主题。
- 用一千个单词,就能进行一次不走偏的交流。
- 最大的模型大约有两万个单词,可以在生成下一个单词之前,考虑到整个上下文,阅读一篇文章、一篇短文或者进行长时间的对话。
最终,一切都取决于模型的大小:越大的模型可以学习更多的关系,考虑到更多的上下文。
GPT的优势和劣势是什么?
GPT 擅长生成看起来像人类写的文本。它能够逻辑连贯地链接思路,辩护自己,适应上下文,扮演角色,而且(尤其是最新的 GPT-4)避免自相矛盾。
不幸的是,它可能会说谎,或者在没有数据的情况下让想象力奔驰。询问数学问题的结果会冒风险得到一个近似的、甚至是错误的答案。考虑到训练数据停留在2021年9月,它将在被问及当前事务时进行创造性发挥。为了避免这种情况发生,Bing Chat 和 Google Bard 将模型连接到一个搜索引擎(Bing 或 Google),让它请求最新的信息。
为了有效地使用 GPT,必须将其应用于模糊和容错的任务(生成营销邮件?),或者很容易由(非 AI!)程序或人类来验证。
模型能够思考吗?
现在我们已经知道它是如何运作的,第一个答案是“不”:该模型是一个光荣的数学方程,可以生成下一个单词的概率。
然而,我们值得去考虑自己的大脑:我们有一个神经元网络(1000亿)彼此连接(每个神经元有10000个连接),对上下文做出反应、从经验中学习,并产生一个适当的(但往往难以准确预测的)答案。换句话说,除了我们的算法是化学而不是数字的这一事实外,它的结构是相似的。
那么它们的不同之处是什么呢?
- 复杂度高出3个数量级:人脑有1000倍于GPT-4参数的连接数量。因此,它可以处理更复杂的情况。
- 持续学习:大脑在对话过程中继续学习,而GPT在对话开始之前就完成了训练。
- 仅限于单词:GPT界面仅限于单词。然而,正如我们所看到的,里面有一个语义系统,在最后一步才被转化回单词。可以想象训练这样的模型来控制机器人(如果有足够的训练数据)。
- 输入受限:GPT所知道的只有通过文本进行的对话。高达60%的人类交流是非语言的:语调、语速、面部表情,甚至一些潜意识因素如气味也起到了作用。而GPT无法捕捉到这一切。
在行为层面,我们还可以找到其他差异:
- GPT在应用逻辑规则方面存在困难,只能尽其所能。具有讽刺意味的是,它不知道如何进行数学运算。但这可以与小孩进行比较。
- GPT没有情感:人类的情感涉及到很多具有复杂和脑部相互作用的激素和腺体。然而,GPT通过人类之间的对话学习了与情感状态相关的行为。它能够表现得好像有情感一样,但这算什么呢?一些对话记录显示,GPT表现得好像知道自己是一个程序,有时会问存在的问题。
- 你可能会认为GPT没有意识。意识的定义经常发生变化,而且这取决于人的观点,但它通常是这样定义的:只有人类才能有意识。如果一个程序表现得与人类无异,我们会认为它有意识吗?中文房间论持相反观点:如果只是按照指令来表现为一个中文说话者而不理解中文,那么计算机只是“按照程序行事”,并不理解中文,因此也不具有意识。
对社会会有何种影响?
我无法预测未来,尤其是在这个革命性技术的拐点上,但要知道的是:这确实是一种革命性技术。对于许多知识工作者,从市场营销到工程师,从招聘人员到社工,GPT都将改变他们的岗位。就像流水线改变了手工艺人的工作一样,计算器和电脑改变了会计,大众传媒改变了政治一样,GPT也将改变知识工作者的世界。
当然,所有这些工作不会一夜之间消失:我们仍然有工匠和会计师,但是在以前需要10人团队的营销部门,现在也许只需要1或2名配备GPT的员工就能胜任。
对于许多科学或工业进步,这种改变将影响许多人:一些人将不得不改变职业或学会将GPT整合到他们的职业中;其他人将失去工作。通过GPT直接创造了新的职位(例如Prompt工程师,那些可以“与机器交流”的人),或通过更轻松地创建产品和公司而间接创造了新职位。确切后果难以确定,但我们正处在一个许多事情都将改变的新阶段,在这个阶段,拥有技术技能的人处于优势地位,而企业家则有了全新的机会。另一方面,许多人没有准备改变,他们没有技能或无法负担再教育的费用,因此受到威胁。
GPT会摧毁社会吗?
有些人担心AI会导致世界末日:从《黑客帝国》到《终结者》,这是末日科幻小说中的常见手法。总的来说,有两种情况:
- 终结者剧情:AI被建造出来赢得一场战争,并获得了军事资源的接近,也许是由狄克推多掌控,AI被赋予了生存本能。人类试图阻止它,AI将其视为威胁,以暴力反应。
- 回形针优化器:在这个寓言中,AI的任务是创造尽可能多的回形针。在耗尽了地球上的可利用资源后,它转向了下一个最可用的碳源:人类。另一个版本看到人类试图阻止机器; AI意识到为了安静地建造回形针,必须摆脱人类。这就像邪恶的精灵一样,它通过给你你想要的东西而不是你真正想要的东西来扭曲你的愿望。
需要认识到的一件事是,目前来说GPT只能生成文本。当然,放在错误的人手中,仅有的文本也可能是危险的(狄克推多典中典之“只是说说而已”),但是单独来看,GPT是无法做任何事情的。不过,它可以成为更强大的系统的第一步:派生出的GPT控制机器人、军事决策助手等。
我们需要谨慎前进,如果进展出乎我们控制,或者至少是无法控制的话,我们需要介入。
令人欣慰的是,一些人工智能专家积极研究防范这些情况的方法,因此可能有一些安全的前进方向。