
在研究了一上午如何给Kindle刷机无果后,我放弃了在Kinlde上使用KOReader的打算。转而研究怎么在电脑上先处理PDF后发送给Kindle看。这个时候我发现了k2pdfopt。
这玩意的原理是不经过OCR,而是大致判断每个字占用多少面积大小,像拼拼图一样把每个字作为一个图案来打乱重拼。我记得核桃以前写过一个用这玩意来做竖版书的软件,但是他博客现在又是关的,看不了……
这个软件的win版是有GUI的,而且我在书伴网站的介绍帖子底下找到了有人发汉化版。那有汉化必不用英文(bushi

先裁边
k2pdfopt理论上也是可以自动裁边的,但是那个裁边效果不好,看到有字就不裁,把页眉页脚也给放进来了。当然这么搞也不影响阅读,只是觉得难看,效果不好。
于是用PDF编辑器来手动裁,我用的软件是ABBYY FineReader,这个切边比较方便。

这里在切边的时候可以分奇数偶数,这对于扫描出版物而言是个很实用的功能,因为扫描书扫出来往往都是左边那一页偏左一点,右边那一页偏右一点。当然一般的书遇到这种情况,那截得胖一点也没什么,大不了左右留点空白,反正等下重排的时候也会去掉的。但是有时候会遇到那种页码标在侧面的书,或者有些翻译书会在侧面标原书页码,这个时候又不想把数字也截进去,不然重排之后好端端一行字里面突然蹦个数字出来,那就得活用这个区分奇数偶数来切边的功能。
当然还有那种做出来就是在网上分发的文字版PDF电子书,那种理论上可以直接用ABBYY的功能另存为epub,不过我没试过,也不知道效果如何。
重排
重排就是用k2pdfopt,win下不用操作命令行,不怎么麻烦。
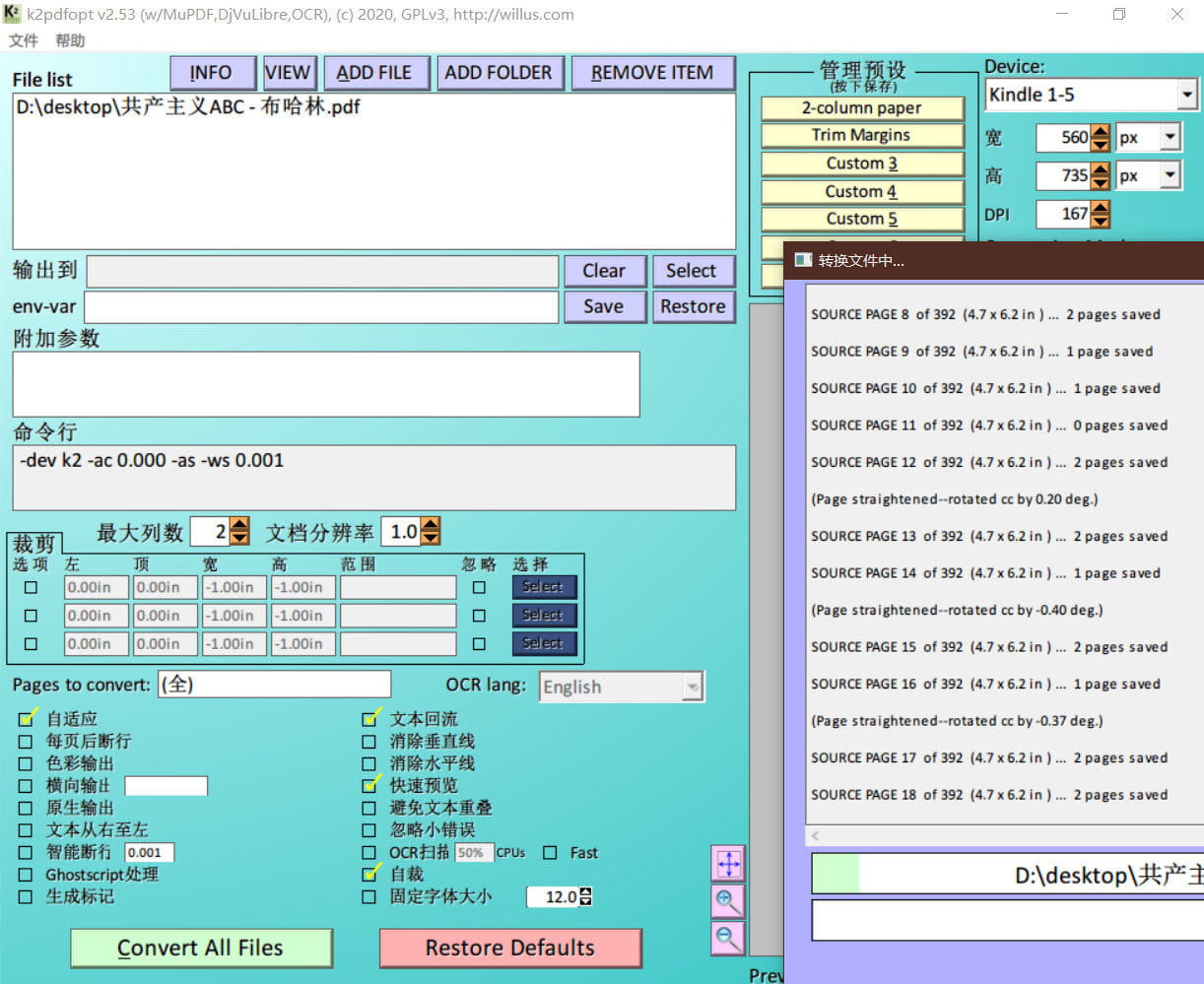
右上角的设备是要调过的,我的kindle型号是KT2,选项里虽然没有,但是想来这台机子比较垃圾,在这里找分辨率最低的 kindle1-5 估计也差不离。
这里默认打开的智能断行(smart line breaks)应该关掉,这个功能是给英文用的,防止一个单词太长被劈成两半写进两行里。因为中文不用担心一个冲字被拆到第一行一个冫在行末,第二行开头半个中字,所以这个没必要开。甚至万一开了,他会按照英文的分词逻辑,把两个标点中间没带空格的中文全部视作一个单词,这个情况下生成的文章立马变成诗歌……
智能断行后面的输入框是字间距,中文的话越小越好,比如我这里是0.001。稍微大点,生成的PDF里字间距就会乱七八糟一会小一会大。
自适应(Autostaighten)则是能在PDF扫描歪了的时候(常有的,一个PDF拿来一看是斜着的)能做点微调,把看起来像是斜着的字给掰正了。
我这里还在附加参数那里输入了-m,这个参数的意思是先智能裁边,然后再进行重排。这个智能裁边,就如我前面所说的,不会裁掉页眉页脚,所以并不是那么好用。如果前面已经先用别的软件裁过一次了,那这里不需要这个参数了。
参数设置完之后直接Convert All Files就成。
压缩
其实到这一步之后这个PDF就已经可用了,拷贝进Kindle里面已经可以看了。就是重排出来的PDF体积巨大,原来这个布哈林的《共产主义ABC》有14M,重排完变成了36M了。
嫌重排出来的文件体积太大可以再去找那种在线压缩PDF的工具,或者本地压缩的话ABBYY也行,不过要我说,这一步搞不搞没啥差别了,照样用。
最后拿来压泡面

看到这个重排效果这么好,我和满书架还没看的书还有steam游戏都笑了。
关于书签
补充一句……
有一些PDF是一页一个书签的,在转换的过程中就会把每一页当作一章,直接换页。

遇到这种PDF还得先把书签重新编辑一遍……